Python Scrapy: Build A Amazon Reviews Scraper [2023]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will scrape Amazon.com product reviews.
Amazon is the most popular e-commerce website for web scrapers with billions of product pages being scraped every month, and is home to a huge database of product reviews. Which can be very useful for market research and competitor monitoring.
In our language agnostic How To Scrape Amazon.com guide, we went into detail about how to Amazon pages are structured and how to scrape Amazon search, product and review pages.
However, in this article we will focus on building a production Amazon scraper using Python Scrapy that will scrape Amazon Product Reviews.
In this guide we will go through:
- How To Build a Amazon Review Scraper
- Paginating Through Amazon Product Reviews
- Storing Data To Database Or S3 Bucket
- Bypassing Amazon's Anti-Bot Protection
- Monitoring To Our Amazon Reviews Scraper
- Scheduling & Running Our Scraper In The Cloud
If you would like to scrape Amazon Products then check out this guide How To Scrape Amazon Products with Scrapy.
GitHub Code
The full code for this Amazon Review Spider is available on Github here.
If you prefer to follow along with a video then check out the video tutorial version here:
How To Build a Amazon Review Scraper
Scraping Amazon reviews is pretty straight forward. We just need a list of product ASIN codes and send requests to the Amazon's product reviews endpoints.
'https://www.amazon.com/product-reviews/B09G9FPHY6/'
Which looks like this:

Amazon ASINs
Amazon uses ASIN (Amazon Standard Identification Number) codes to identify product. Every product listed on Amazon has its own unique ASIN code, which you can use to construct URLs to scrape that product page, reviews, or other sellers.
From here, we just need to create a Scrapy spider that will parse the review data from the page.
The following is a simple Scrapy spider that will request the product reviews for every ASIN in the asin_list list, and then parse the review data from the response.
import scrapy
from urllib.parse import urljoin
class AmazonReviewsSpider(scrapy.Spider):
name = "amazon_reviews"
def start_requests(self):
asin_list = ['B09G9FPHY6']
for asin in asin_list:
amazon_reviews_url = f'https://www.amazon.com/product-reviews/{asin}/'
yield scrapy.Request(url=amazon_reviews_url, callback=self.parse_reviews, meta={'asin': asin})
def parse_reviews(self, response):
asin = response.meta['asin']
## Parse Product Reviews
review_elements = response.css("#cm_cr-review_list div.review")
for review_element in review_elements:
yield {
"asin": asin,
"text": "".join(review_element.css("span[data-hook=review-body] ::text").getall()).strip(),
"title": review_element.css("*[data-hook=review-title]>span::text").get(),
"location_and_date": review_element.css("span[data-hook=review-date] ::text").get(),
"verified": bool(review_element.css("span[data-hook=avp-badge] ::text").get()),
"rating": review_element.css("*[data-hook*=review-star-rating] ::text").re(r"(\d+\.*\d*) out")[0],
}
Now when we run our scraper:
scrapy crawl amazon_reviews
The output of this code will look like this:
[{"text": "Ok..little old lady here, whose working life consisted of nothing but years and years of Windows, android phones, etc. Just in last several years jumped hesitantly into Apple (phone, Ipad mini, etc.)LOVE LOVE LOVE my iPad mini but, thought..might be time to think about replacement..so, I saw the great price on this 10 inch tablet and thought Id take a chance. I am much more partial to the mini sized tablets, but thought Id go for it...soooo, even after reading all the bu.......t comments here, thought Id try, if i didnt like it., Id return it. 1. Delivered on time, yayyy! 2. Package well protected, sealed, unblemished...perfect condition (and yeah..no fingerprints on screen) 3. Ipad fired right up...70% charged 4. Ipad immediately began transferring info from iPhone that was sitting nearby. Yayyyyy!! No need for reams of books, booklets, warnings, etc., etc.!! 5. EVERYTHING transferred from iPhone and IPad Mini...and I still had some 15 gig storage left on new 64 gig iPad (just remember ...this is for my entertainment...not for work with diagrams, idiotic work related emails about cleaning up my workspace, or 20 specs for items no one will ever use) 6. Did a test run...everything worked exactly as I required, expected. 7. Ultimate test...watched old Morse/Poirot shows I have in Prime..excellent quality! love love love 8. After 8 full hours...I had to recharge for a bit before I went to bed. (charged fairly fast!)sooooooo...Im keeping this jewel!!!!!Risk is there...evidently, if you believe the nutso crowd and their comments here. Its a GREAT item, its a fabulous deal, Christmas is coming...or if you need to have a worthy backup..,...DO IT!!!!",
"title": "EXCELLENT buy!",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 10, 2022",
"verified": true,
"rating": "5.0"},
{"text": "If you’re anything like me you want something to watch shows on in you living room or bed, but you don’t like the TV, and your phone is too small. Well this is the perfect thing for you, the screen is just the right size and very crisp and clear(maybe better then my iPhone X), the responsiveness is excellent, and all of the streaming sites work with this perfectly. On top of that, my AirPods automatically switch between this and my phone, so I don’t have to worry about messing with the settings every time. However, the camera is only OK. And it feels very delicate, so I would pick up a case and get AppleCare+. The battery isn’t the best either, but should be enough to get through the day. Overall I definitely recommend this, especially for the price.",
"title": "Perfect",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 13, 2022",
"verified": true,
"rating": "5.0"},
{"text": "My old IPad was acting up, wouldn’t hold a charge etc. This iPad arrived the very next day after I ordered it. What a great surprise. The one corner of the outer box it arrived in was damaged, but the inner box containing the iPad was in perfect condition. It was so simple to transfer everything from my old iPad to this one, just laid the new one on the old (iPad 2019) and it did pretty much everything on its own. I am very pleased with my purchase, I hope it lasts longer than my 2019 model.",
"title": "Great purchase",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 15, 2022",
"verified": true,
"rating": "5.0"},
{"text": "Im not much of an apple product person but I do buy them for people I dont want to provide tech support to. (Parents, In-laws, Wife, and Kids)I used to use the fire tablets because they were cheap and I thought that would keep the kids entertained, especially on road trips. This worked for movies and some games but there were always problems with how slow they become with updates, loss of battery life, etc.This ipad was a game changer. I always knew they were the best tablets but I was also a bit in denial as well as just being somewhat anti-apple. With this on sale during prime day 2022 (July) I took a chance and bought one for the kids.This does everything as well or better (usually better) than previous tablets I had purchased because they were cheaper.I also didnt buy a case for it and my kids are brutal with these types of devices. To date, it is still in one piece, operational, and has no cracks in the screen.Sometimes it is worth paying a bit more for the name brand product and in this case Im a believer.",
"title": "Kids love it",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 2, 2022",
"verified": true,
"rating": "5.0"},
{"text": "For those who wonder, this is brand new in the box, 2021 9th generation. It is NOT refurbed or an exchange. It is never opened and shrink wrapped by Apple. (See my photos.) The reason it is so much cheaper than the other 2021 iPads is the 64gb storage. But with iCloud so ridiculously cheap for cloud storage, I just cannot see this 64gb as not getting the job done. I myself was curious about this low price buying me a refurb/exchange, but that is simply not the case here. I do, however, recommend you not go with 32gb. I believe even with an iCloud account, you will be sorry you didn’t go 64gb.And the ease of setting this up cannot be understated. I simply sat my iPhone 13 Pro Max next to it and all relevant files and Wi-Fi passwords were transferred over with no input from me. It looked to me that it will do that with Android and most laptops also, though I did not test that out. All photos also came over, and the ones I took after that transfer, I simply Air-Dropped them into this iPad. All in all, this is as simple as it gets for transferring files and photos. Apple has this stuff down to a science, believe me.This screen is incredible. If you are looking at a pre-Retina screen, you will be amazed at this 2021 version. This thing is very fast, the on screen keyboard is fast, accurate and very concise. Dealing with apps is easy, and Apple doesn’t load you down with bloat you’ll never use. It is claimed this has about 12 hours on a charge; what I’ve seen thus far leads me to believe that is accurate.All in all, I am extremely pleased with this purchase. You can’t always say you got what you paid for. But I can definitely say that with this. This is the entry level 2021 9th generation iPad, and it is exactly what I need. Go and get you one…",
"title": "Incredible deal on incredible machine",
"location_and_date": "Reviewed in the United States 🇺🇸 on September 21, 2022",
"verified": true,
"rating": "5.0"},
{"text": "I bought this for my husband. He loves it! It is the gift that really does keep on giving. It arrived quickly, well packaged and I didn’t have to leave my house to get it. It was great to use my iPad to purchase this one as a gift and have it arrive safe.y. Thank you, Amazon!",
"title": "Best gift 🎁",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 15, 2022",
"verified": true,
"rating": "5.0"},
{"text": "I have had an ipad air since they came out. I used hotel points to get it and its served me well as a book and simple internet use. Recently I noticed that it was no updating and some of my favorite apps were telling me they were using an old version because my IOS was outdated. Without being able to update it I decided to pass my old one on and get a new one. Then I thought Id get a mini 6 but after comparing the prices and the ability I could not justify a double price for it. I ordered this Ipad 9 and it came quicker than expected. Out of the box it performs much better than my old one, screen appears clearer and I like the new IOS it uses. My old one will live on as a small tv for my wife when shes in the kitchen and for that it does very well. I have no complaints about my new one. Its easy to talk yourself into the top of the curve, but sometimes being a bit behind it makes better fiscal sense",
"title": "My old Ipad was too old to update, so it was passed down,",
"location_and_date": "Reviewed in the United States 🇺🇸 on September 25, 2022",
"verified": true,
"rating": "5.0"},
{"text": "I have always been an android user. I finally dipped my toe into Apple. There is a learning curve, I do not speak Apple. Thankfully I have grandchildren and they have taught me a lot. Dont snooze on this one, I love it, fast, images clearer, pics, videos, pen, everything about this one is great. I now get the Apple craze.",
"title": "Perfect size and performance",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 13, 2022",
"verified": true,
"rating": "5.0"},
{"text": "El iPad es una tableta muy fácil de usar y muy práctica puedes hacer casi todo lo que necesitas en el día a día, oficina, escuela, entretenimiento, productividad, y con 256gb tengo para almacenar mucha información.",
"title": "El iPad es la mejor tableta que existe",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 14, 2022",
"verified": true,
"rating": "5.0"},
{"text": "Thought I was gonna get a knock off for the price but came brand new, no problems what so ever. Amazing battery life I charge it every two days and use it constantly at school and work for studying and job demands.",
"title": "Excellent product",
"location_and_date": "Reviewed in the United States 🇺🇸 on October 14, 2022",
"verified": true,
"rating": "5.0"}]
The problem with the above spider is that it will only request the first page of product reviews for each product.
However, each product can have can tens to hundreds of product review pages. To solve this we need to configure our spider to paginate through all the available product pages.
Paginating Through Amazon Product Reviews
The above code works, but it just extracts all the product reviews from a single Amazon reviews page.
However, we can expand the scraper to paginate through all the product review pages and scrape the product reviews from every page by checking if there is another page.
In our parse_reviews function we will add the following code:
def parse_reviews(self, response):
asin = response.meta['asin']
## Get Next Page Url
next_page_relative_url = response.css(".a-pagination .a-last>a::attr(href)").get()
if next_page_relative_url is not None:
next_page = urljoin('https://www.amazon.com/', next_page_relative_url)
yield scrapy.Request(url=next_page, callback=self.parse_reviews, meta={'asin': asin})
...
This code which will:
- Check if the page contains a "Next Page" link.
- If the page does contain a "Next Page" link then it will extract the relative URL.
- Convert the relative URL into a absolute URL and then request this page.
- This loop will continue until the reviews page doesn't contain any more "Next Page" links.
Here is the full code for the Amazon reviews spider.
import scrapy
from urllib.parse import urljoin
class AmazonReviewsSpider(scrapy.Spider):
name = "amazon_reviews"
def start_requests(self):
asin_list = ['B09G9FPHY6']
for asin in asin_list:
amazon_reviews_url = f'https://www.amazon.com/product-reviews/{asin}/'
yield scrapy.Request(url=amazon_reviews_url, callback=self.parse_reviews, meta={'asin': asin, 'retry_count': 0})
def parse_reviews(self, response):
asin = response.meta['asin']
retry_count = response.meta['retry_count']
## Get Next Page Url
next_page_relative_url = response.css(".a-pagination .a-last>a::attr(href)").get()
if next_page_relative_url is not None:
retry_count = 0
next_page = urljoin('https://www.amazon.com/', next_page_relative_url)
yield scrapy.Request(url=next_page, callback=self.parse_reviews, meta={'asin': asin, 'retry_count': retry_count})
## Adding this retry_count here to bypass any amazon js rendered review pages
elif retry_count < 3:
retry_count = retry_count+1
yield scrapy.Request(url=response.url, callback=self.parse_reviews, dont_filter=True, meta={'asin': asin, 'retry_count': retry_count})
## Parse Product Reviews
review_elements = response.css("#cm_cr-review_list div.review")
for review_element in review_elements:
yield {
"asin": asin,
"text": "".join(review_element.css("span[data-hook=review-body] ::text").getall()).strip(),
"title": review_element.css("*[data-hook=review-title]>span::text").get(),
"location_and_date": review_element.css("span[data-hook=review-date] ::text").get(),
"verified": bool(review_element.css("span[data-hook=avp-badge] ::text").get()),
"rating": review_element.css("*[data-hook*=review-star-rating] ::text").re(r"(\d+\.*\d*) out")[0],
}
Now when we run this spider, it will scrape every review from every review page for each ASIN we add to the asin_list.
Storing Data To Database Or S3 Bucket
With Scrapy, it is very easy to save our scraped data to CSV files, databases or file storage systems (like AWS S3) using Scrapy's Feed Export functionality.
To configure Scrapy to save all our data to a new CSV file everytime we run the scraper we simply need to create a Scrapy Feed and configure a dynamic file path.
If we add the following code to our settings.py file, Scrapy will create a new CSV file in our data folder using the spider name and time the spider was run.
# settings.py
FEEDS = {
'data/%(name)s_%(time)s.csv': {
'format': 'csv',
}
}
If you would like to save your CSV files to a AWS S3 bucket then check out our Saving CSV/JSON Files to Amazon AWS S3 Bucket guide here
Or if you would like to save your data to another type of database then be sure to check out these guides:
- Saving Data to JSON
- Saving Data to SQLite Database
- Saving Data to MySQL Database
- Saving Data to Postgres Database
Bypassing Amazon's Anti-Bot Protection
As you might have seen already if you run this code Amazon might be blocking you and returning a error page like this:

Or telling you that if you want automated access to their data reach out to them.
This is because Amazon uses anti-bot protection to try and prevent (or at least make it harder) developers from scraping their site.
You will need to using rotating proxies, browser-profiles and possibly fortify your headless browser if you want to scrape Amazon reliably at scale.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our Amazon Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://amazon.com'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy Proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and Amazon won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your Amazon Reviews Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
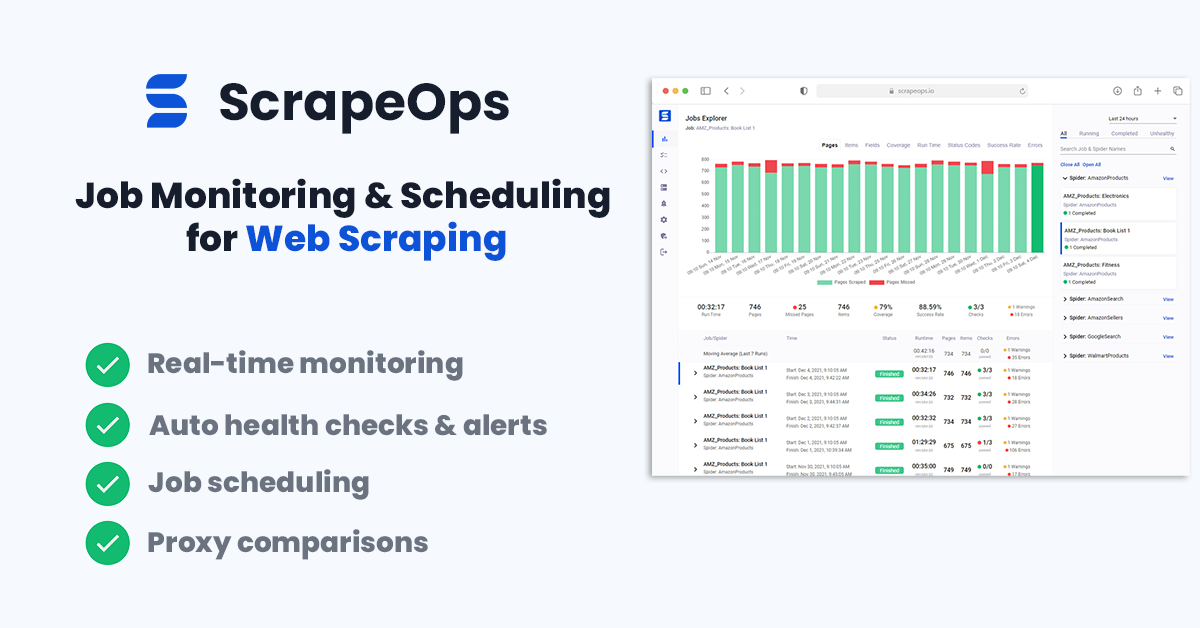
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run a our Amazon spider (scrapy crawl amazon_reviews), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our Amazon scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape Amazon.com including how to bypass its anti-bot protection.
The full code for this Amazon Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides here:
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: