Python Scrapy: Build A LinkedIn Jobs Scraper [2023]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will scrape LinkedIn.com jobs.
LinkedIn is one of the most up-to-date and extensive source of jobs on the internet. As a result it is the most popular web scraping target of recruiting, HR and lead generation companies.
In this article we will focus on building a production LinkedIn spider using Python Scrapy that will scrape LinkedIn Jobs.
In this guide we will go through:
- How To Build a LinkedIn Jobs Scraper
- Bypassing LinkedIn's Anti-Bot Protection
- Monitoring To Our LinkedIn Jobs Scraper
- Scheduling & Running Our Scraper In The Cloud
GitHub Code
The full code for this LinkedIn Jobs Spider is available on Github here.
Scraping LinkedIn Jobs
Since this Scrapy spider scrapes from the LinkedIn jobs API endpoint it can be very unreliable due to LinkedIn agressivly preventing any scraping of their endpoints. So be warned that it may or may not work - even when using proxy providers to by pass the anti-bots.
If you prefer to follow along with a video then check out the video tutorial version here:
How To Build a LinkedIn Jobs Scraper
Scraping LinkedIn Jobs is pretty straight forward, once you have the HTML response (Getting the HTML is the hard part, which we will discuss later).
To start off we just need to go to the public jobs page - this page is available without being logged in which makes scraping the data so much easier.
Just go to the link below to see the jobs page.
'https://www.linkedin.com/jobs/search'
It should look something like this:

So instead of scraping the data directly from the page itself we can first check the network requests to see if there are any API requests being made directly to the LinkedIn API backend which might be requesting the data we need.
If there is an API request being made and the job data returning then we can just scrape the response of these requests instead of the main page itself.
This would make coding our spider easier and much cheaper as we wouldn't have to deal with any Javascript rendering of pages or any manual actions on the page (such as scrolling to the bottom to load in the next set of results).
OK - let's add in a job title we want to search for. For this tutorial I'm going to add in "Python" to the "Job Title or Companies" input field and "United States" for the Location input field and click search. The page should now only be displaying us the Python jobs in the United States.

Now, open up the developer tools on the page and open the network tab. (Right click in your browser, then "Inspect")
Lets scroll to the bottom of the jobs page so it loads in some more jobs. You will notice that each time a new set of 25 jobs is loaded into the page a request is sent to:
'https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=python&location=United%20States&start=25'
We can see it in the bottom left (highlighed in blue) where it comes up as:
'search?keywords=python&location=United%20States&start=25'

In the 'Preview' tab for the request on the right of the devtools you can see what the response that is being sent back from LinkedIn contains. In this case - it contains job data!
This shows us that we can use the LinkedIn API calls to collect the data. We can use the URL and the request paramaters to get back the jobs we need. The API end point only gives us a maximum of 25 jobs back in each response, so we will need to work around that to get multiple pages of job data back.
In the "Headers" & "Payload" tabs of the network tab we can see what is being sent to LinkedIn, as well as the full url we will need to make the scrapy request:


In the "Response" tab we can see the raw html code which we will be parsing using our CSS selectors in our scrapy spider code.

The following code is a simple Scrapy spider that will request the first 25 jobs for "Python" & "United States" from the linkedIn API endpoint and then parse the job details from the response. As you can see both search terms we are searching for are in the api_url variable. You can change these to be what ever job title and location that you need.
import scrapy
class LinkedJobsSpider(scrapy.Spider):
name = "linkedin_jobs"
api_url = 'https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=python&location=United%2BStates&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit&start='
def start_requests(self):
first_job_on_page = 0
first_url = self.api_url + str(first_job_on_page)
yield scrapy.Request(url=first_url, callback=self.parse_job, meta={'first_job_on_page': first_job_on_page})
def parse_job(self, response):
first_job_on_page = response.meta['first_job_on_page']
job_item = {}
jobs = response.css("li")
num_jobs_returned = len(jobs)
print("******* Num Jobs Returned *******")
print(num_jobs_returned)
print('*****')
for job in jobs:
job_item['job_title'] = job.css("h3::text").get(default='not-found').strip()
job_item['job_detail_url'] = job.css(".base-card__full-link::attr(href)").get(default='not-found').strip()
job_item['job_listed'] = job.css('time::text').get(default='not-found').strip()
job_item['company_name'] = job.css('h4 a::text').get(default='not-found').strip()
job_item['company_link'] = job.css('h4 a::attr(href)').get(default='not-found')
job_item['company_location'] = job.css('.job-search-card__location::text').get(default='not-found').strip()
yield job_item
Now when we run our scraper:
scrapy crawl linkedin_jobs
The output of this spider will look like this (we've just listed the data from one job but many will be returned!):
{
"job_title": "Python",
"job_detail_url": "https://www.linkedin.com/jobs/view/python-at-tekvivid-inc-3399462007?refId=gp%2BAUq%2F0FaeOqQ97Rr8qsQ%3D%3D&trackingId=x9Qvh8AW3HntMfy%2Fj7IoSw%3D%3D&position=1&pageNum=0&trk=public_jobs_jserp-result_search-card",
"job_listed": "1 day ago",
"company_name": "TekVivid, Inc",
"company_link": "https://www.linkedin.com/company/tekvividinc?trk=public_jobs_jserp-result_job-search-card-subtitle",
"company_location": "Texas, United States"
},
This spider scrapes the following data from the LinkedIn job:
- Job title
- Job detail url - the url to the full job description & more details
- Job listed - when the job was listed
- Company name - the company name
- Company link - the url for the company page where there are more details on the company
- Company location
You can expand this spider to scrape other details by simply adding to the parse_job method and following the same format.
Using the above code snippit will only get us the data of the first 25 jobs.
Next let's look at how we can request the next set of 25 job postings from the LinkedIn Api until we have finished collecting all the jobs that we have searched for.
How To Request Multiple Pages from LinkedIn's API
Lets expand our parse_job function now to keep on requesting the next 25 jobs until there are no more jobs left for us to scrape.
We do this by incrementing first_job_on_page by 25 each time. This means that the next_url that's passed into the scrapy.Request function will be getting the next 25 jobs.
We have a check to see if num_jobs_returned is greater than 0 but that can be a bit redundent as if the url doesn't exist due to us looking for too many jobs (Say the 5,000,0000,000th Scrapy job for example) then the LinkedIn API will return a 400 error and our spider will stop scraping. Still it's better to have the check there just incase!
The full code for the spider should now look like the following:
def parse_job(self, response):
first_job_on_page = response.meta['first_job_on_page']
job_item = {}
jobs = response.css("li")
num_jobs_returned = len(jobs)
print("******* Num Jobs Returned *******")
print(num_jobs_returned)
print('*****')
for job in jobs:
job_item['job_title'] = job.css("h3::text").get(default='not-found').strip()
job_item['job_detail_url'] = job.css(".base-card__full-link::attr(href)").get(default='not-found').strip()
job_item['job_listed'] = job.css('time::text').get(default='not-found').strip()
job_item['company_name'] = job.css('h4 a::text').get(default='not-found').strip()
job_item['company_link'] = job.css('h4 a::attr(href)').get(default='not-found')
job_item['company_location'] = job.css('.job-search-card__location::text').get(default='not-found').strip()
yield job_item
#### REQUEST NEXT PAGE OF JOBS HERE ######
if num_jobs_returned > 0:
first_job_on_page = int(first_job_on_page) + 25
next_url = self.api_url + str(first_job_on_page)
yield scrapy.Request(url=next_url, callback=self.parse_job, meta={'first_job_on_page': first_job_on_page})
Let's go ahead and run that now with scrapy crawl linkedin_jobs and you should see the spider looping through and scraping all the pages until it can't find any more jobs to scrape!
Bypassing LinkedIn's Anti-Bot Protection
As mentioned above, LinkedIn has one of the most aggressive anti-scraping systems on the internet, making it very hard to scrape.
It uses a combination of IP address, headers, browser & TCP fingerprinting to detect scrapers and block them.
As you might have seen already, if you run the above code LinkedIn is likely blocking your requests and returning their login page like this:

Public LinkedIn Jobs
This Scrapy spider is only designed to scrape public LinkedIn jobs that don't require you to login to view. Scraping behind LinkedIn's login is significantly harder and opens yourself up to much higher legal risks.
To bypass LinkedIn's anti-scraping system will need to using very high quality rotating residential/mobile proxies, browser-profiles and a fortified headless browser.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator which integrates with over 20+ proxy providers and finds the proxy solution that works best for LinkedIn for you.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our LinkedIn Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=python&location=United%2BStates&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit&start=0'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy Proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and LinkedIn won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your LinkedIn Jobs Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
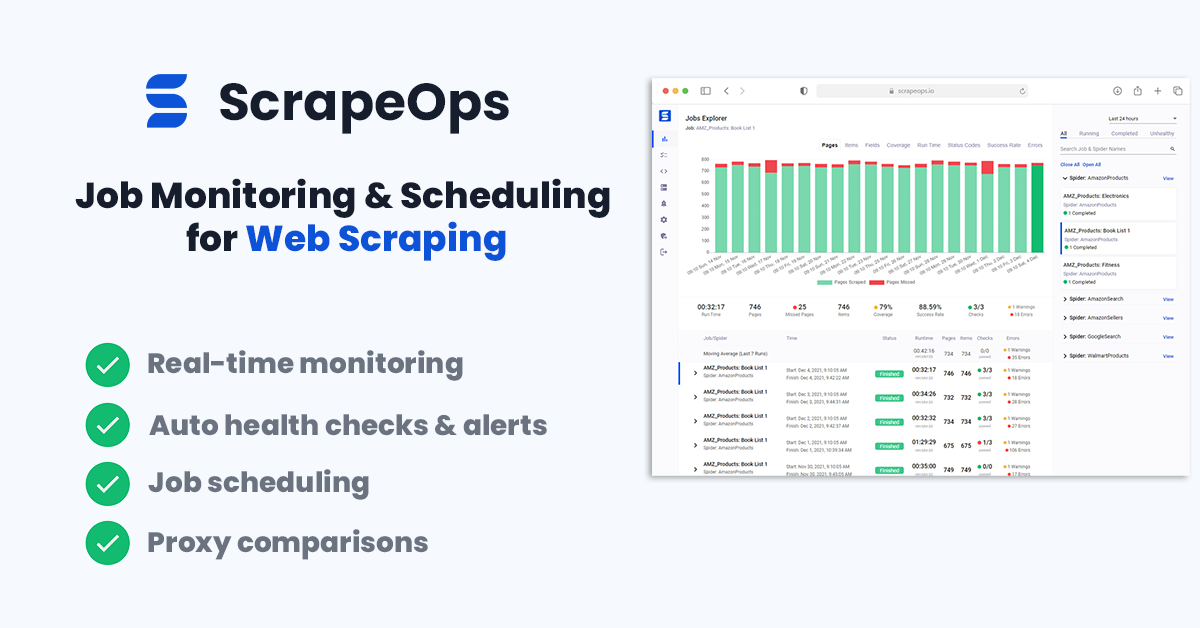
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run a our LinkedIn Job spider (scrapy crawl linkedin_jobs), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our LinkedIn People Profile scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape LinkedIn.com including how to bypass its anti-bot protection.
The full code for this LinkedIn Jobs Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides here:
- How To Scrape Amazon Products
- How To Scrape Amazon Product Reviews
- How To Scrape Walmart.com
- How To Scrape Indeed.com
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: