Scrapy Javascript Rendering: The 4 Best Scrapy Libraries to Scrape JS Heavy Websites
With the growing popularity of single page applications built with React.js, Angular.js, Vue.js, etc. scraping data is becoming more complicated.
Oftentimes, you send a request to a website but the data you need isn't in the response because it is rendered client side in the browser, or you need to interact with the page to get access to the data.
When this occurs you will likely need to use a Headless browser to render the on-page Javascript before trying to parse the data from the response.
So this this guide we're going to walk through the 4 Best Javascript Rendering Libraries for Scrapy:
1. Scrapy Playwright
The first option on the list is scrapy-playwright, a library that allows you to effortlessly use Playwright.js in your Scrapy spiders.
Of the options on the list, scrapy-playwright is the most up to date, easiest to use and probably the most powerful library available.
Scrapy Playwright Integration
Simply install scrapy-playwright and playwright itself:
pip install scrapy-playwright
playwright install
And then set it up in your Scrapy project by adding 2 settings:
# settings.py
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
From there, to render a page with Playwright you just need to add the flag 'playwright': True to the Request meta dictionary when makes a request and these requests will use Playwright.
# spiders/quotes.py
import scrapy
from scrapy_playwright_demo.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = "https://quotes.toscrape.com/js/"
yield scrapy.Request(url, meta={'playwright': True})
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
scrapy-playwright allows you to use the all the Playwright functionality you will ever need when scraping a website.
- Wait for elements to load before returning response
- Scrolling the page
- Clicking on page elements
- Taking a screenshot of the page
- Creating PDFs of the page
- Use Proxies
- Create browser contexts
Note: As of writing this guide, the only major drawback to Scrapy Playwright is that doesn't work with Windows. However, it is possible to run it with WSL (Windows Subsystem for Linux)
If you would like to learn more about Scrapy Playwright then you are check out our Scrapy Playwright Guide, or the scrapy-playwright documentation.
2. Scrapy Splash
Next, up is scrapy-splash which was developed by many of the core Scrapy developers.
Scrapy Splash is a light weight browser that spins up a HTTP server and which you render pages with by sending urls to request over its HTTP API.
At this point, Scrapy Splash is a bit outdated, having being overtaken by Playwright and Puppeteer headless browsers, but it still is a very capable headless browser for web scraping.
Like other headless browsers you can tell Scrapy Splash to do certain actions before returning the HTML response to your spider.
Splash can:
- Wait for page elements to load
- Scroll the page
- Click on page elements
- Take screenshots
- Turn off images or use Adblock rules to make rendering faster
It has comprehensive documentation, has been heavily battletested for scraping and Zyte offers hosted Splash instances so you don't need to manage the browsers themselves.
The main drawbacks with Splash is that it can be a bit harder to get started as a beginner, as you to run the Splash docker image and to control the browser you use Lua scripts. But once you get familiar with Splash it can cover most scraping tasks.
Scrapy Splash Integration
Getting up and running with Splash isn't quite as straight forward as other options but is still simple enough:
1. Download Scrapy Splash
First we need to download the Scrapy Splash Docker image:
docker pull scrapinghub/splash
2. Run Scrapy Splash
To run Scrapy Splash, we need to run the following command in our command line again.
docker run -it -p 8050:8050 --rm scrapinghub/splash
To check that Splash is running correctly, go to http://localhost:8050/ and you should see the following screen.

If you do then, Scrapy Splash is up and running correctly.
3. Integrate Into Scrapy Project
To use Scrapy Splash in our project, we first need to install the scrapy-splash downloader.
pip install scrapy-splash
Then we need to add the required Splash settings to our Scrapy projects settings.py file.
# settings.py
# Splash Server Endpoint
SPLASH_URL = 'http://192.168.59.103:8050'
# Enable Splash downloader middleware and change HttpCompressionMiddleware priority
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# Enable Splash Deduplicate Args Filter
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Define the Splash DupeFilter
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
4. Use Scrapy Splash In Spiders
To actually use Scrapy Splash in our spiders to render the pages we want to scrape we need to change the default Request to SplashRequest in our spiders.
# spiders/quotes.py
import scrapy
from demo.items import QuoteItem
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(url, callback=self.parse)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
Now all our requests will be made through our Splash server and any javascript on the page will be rendered.
If you would like to learn more about Scrapy Splash then you are check out our Scrapy Splash Guide.
3. Scrapy Selenium
Next, up is scrapy-selenium which provides a Scrapy integration with the popular headless browser Selenium.
Originally designed for automated testing of web applications, as websites became ever more Javascript heavy developers increasingly began to use Selenium for web scraping.
For years, Selenium was the most popular headless browser for web scraping (especially in Python), however, since the launch of Puppeteer and Playwright it has begun to fall out of favour.
To use Selenium in your Scrapy spiders you can use the Python Selenium library directly or else use scrapy-selenium.
The first option of importing Selenium into your Scrapy spider works but isn't the cleanest implementation.
As a result, scrapy-selenium which was a Playwright style integration with Scrapy, making it much easier to use.
Note: However, scrapy-selenium hasn't been maintained in over 2 years, so it is recommended to use scrapy-playwright instead as it is a more powerful headless browser and is actively maintained by the Scrapy community.
Scrapy Selenium Integration
Getting setup with Scrapy Selenium can be easy, but also a bit tricky as you need to install and configure a browser driver for scrapy-selenium to use.
1. Install Scrapy Selenium
To get started we first need to install scrapy-selenium by running the following command:
pip install scrapy-selenium
Note: You should use Python Version 3.6 or greater. You also need one of the Selenium compatible browsers.
2. Install ChromeDriver
To use scrapy-selenium you first need to have installed a Selenium compatible browser.
In this guide, we're going to use ChromeDiver which you can download from here.
You will need to download the ChromeDriver version that matches the version of Chrome you have installed on your machine.
To find out what version you are using, go to Settings in your Chrome browser and then click About Chrome to find the version number.
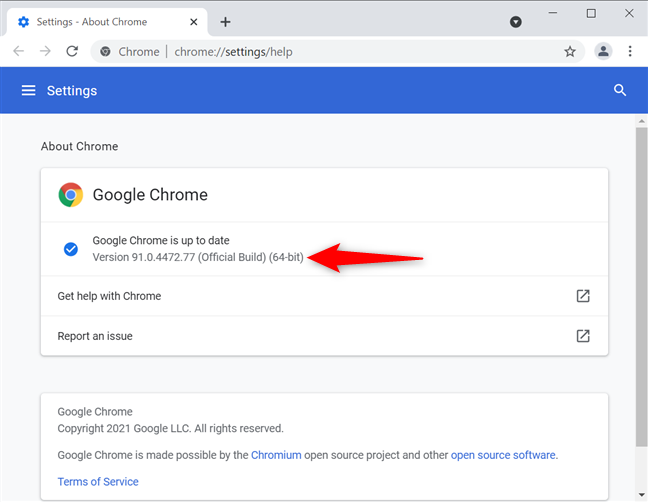
We should put the downloaded chromedriver.exe in our Scrapy project here:
├── scrapy.cfg
├── chromedriver.exe ## <-- Here
└── myproject
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
3. Integrate Scrapy Selenium Into Project
To integrate scrapy-selenium, we need to update our settings.py file with the following settings.
## settings.py
# for chrome driver
from shutil import which
SELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver')
SELENIUM_DRIVER_ARGUMENTS=['--headless']
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}
4. Update Our Spiders To Use Scrapy Selenium
Then to use Scrapy Selenium in our spiders to render the pages we want to scrape we need to change the default Request to SeleniumRequest in our spiders.
## settings.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(url=url, callback=self.parse)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
Now all our requests will be made through our Splash server and any javascript on the page will be rendered.
For a deeper dive into Scrapy Selenium then be sure to check our Scrapy Selenium guide, and the official docs.
4. Scrapy Puppeteer
Finally, there is Puppeteer and the Scrapy Integration scrapy-pyppeteer which enables you to use Pyppeteer as your Download Handler.
Pyppeteer is a unofficial Python port of the JavaScript (headless) chrome/chromium browser automation library Puppeteer, which has gained popularity amongst web scrapers when scraping JS heavy websites and when making bots.
scrapy-pyppeteer had lots of potential, however, currently it is unmaintained and they publically recommend that you use scrapy-playwright instead.
However, if you would still like to give it a try here is how you integrate it.
Scrapy Pyppeteer Integration
Getting setup with Scrapy Pyppeteer is pretty easy.
1. Install Scrapy Pyppeteer
To get started we first need to install scrapy-pyppeteer by running the following command:
pip install scrapy-pyppeteer
2. Integrate Scrapy Pyppeteer Into Project
To integrate scrapy-pyppeteer, we need to update our settings.py file with the following settings.
## settings.py
DOWNLOAD_HANDLERS = {
"http": "scrapy_pyppeteer.handler.ScrapyPyppeteerDownloadHandler",
"https": "scrapy_pyppeteer.handler.ScrapyPyppeteerDownloadHandler",
}
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
The ScrapyPyppeteerDownloadHandler class inherits from the default http/https handler, so it will only use Pyppeteer for requests that have Pyppeteer explicitly enabled.
3. Update Our Spiders To Use Scrapy Pyppeteer
Like Scrapy Playwright, to use Scrapy Pyppeteer in our spiders to render the pages we want to scrape, we just need to add meta={"pyppeteer": True} to our spiders requests.
## settings.py
import scrapy
from pyppeteer_demo.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield scrapy.Request(url=url, callback=self.parse, meta={"pyppeteer": True})
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
With meta={"pyppeteer": True} set, all requests will be requests and rendered using Pyppeteer.
For more detailed information on configuring scrapy-pyppeteer then check out the official docs here.
More Scrapy Tutorials
In this guide we introduced you to all the major headless browser integrations for Scrapy.
If you would like to learn more about a specific Javascript rendering option, then be sure to check out our more detailed guides:
If you would like to learn more about Scrapy in general, then be sure to check out The Scrapy Playbook.