Scrapy Selenium Guide: Integrating Selenium Into Your Scrapy Spiders
Originally designed for automated testing of web applications, over the years Selenium became the go to headless browser option for Python developers looking to scrape JS heavy websites.
Selenium gave you the ability to scrape websites that needed to be rendered or interacted with to show all the data.
For years, Selenium was the most popular headless browser for web scraping, however, since the launch of Puppeteer and Playwright Selenium has begun to fall out of favour.
That being said, Selenium is still a powerful headless browser option and every web scraper should be aware of it.
Although, you could use the Python Selenium library directly in your spiders (it can be a bit clunky), in this guide we're going to use scrapy-selenium which provides a much better integration with Scrapy.
In this guide we're going to walk through how to setup and use Scrapy Splash, including:
Note: scrapy-selenium hasn't been maintained in over 2 years, so it is recommended you check out scrapy-playwright as well as it is a more powerful headless browser and is actively maintained by the Scrapy community.
Integrating Scrapy Selenium
Getting setup with Scrapy Selenium is easier to get setup than Scrapy Splash, but not as easy as Scrapy Splash as you need to install and configure a browser driver for scrapy-selenium to use it. Which can be a it prone to bugs.
1. Install Scrapy Selenium
To get started we first need to install scrapy-selenium by running the following command:
pip install scrapy-selenium
Note: You should use Python Version 3.6 or greater. You also need one of the Selenium compatible browsers.
2. Install ChromeDriver
To use scrapy-selenium you first need to have installed a Selenium compatible browser.
In this guide, we're going to use ChromeDiver which you can download from here.
You will need to download the ChromeDriver version that matches the version of Chrome you have installed on your machine.
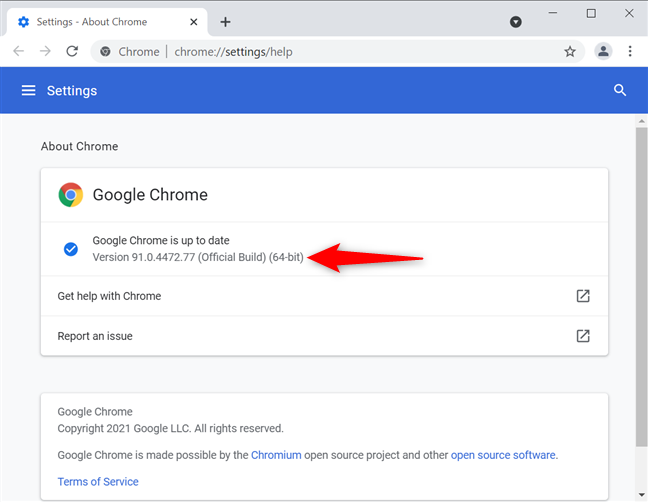
To find out what version you are using, go to Settings in your Chrome browser and then click About Chrome to find the version number.
We should put the downloaded chromedriver.exe in our Scrapy project here:
├── scrapy.cfg
├── chromedriver.exe ## <-- Here
└── myproject
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
3. Integrate Scrapy Selenium Into Project
Next we need to integrate scrapy-selenium into our project by updating our settings.py file with the following settings if using a Chrome driver:
## settings.py
# for Chrome driver
from shutil import which
SELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver')
SELENIUM_DRIVER_ARGUMENTS=['--headless']
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}
Or these settings if using a FireFox driver:
## settings.py
# For Firefox driver
from shutil import which
SELENIUM_DRIVER_NAME = 'firefox'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('geckodriver')
SELENIUM_DRIVER_ARGUMENTS=['--headless']
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}
4. Update Our Spiders To Use Scrapy Selenium
Then to use Scrapy Selenium in our spiders to render the pages we want to scrape we need to change the default Request to SeleniumRequest in our spiders.
## spider.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(url=url, callback=self.parse)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
Now all our requests will be made through our Splash server and any javascript on the page will be rendered.
We can use the response, like we would normally.
Controlling Scrapy Selenium
Like other headless browsers you can configure Scrapy Selenium to do certain actions before returning the HTML response to your spider.
Splash can:
- Wait for page elements to load
- Scroll the page
- Click on page elements
- Take screenshots
- Turn off images or use Adblock rules to make rendering faster
1. Wait For Time
You can tell Scrapy Selenium to wait X number of seconds for updates after the initial page has loaded to make sure you get all the data you need by adding a wait_time agrument to your request:
## spider.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(url=url, callback=self.parse, wait_time=10)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
2. Wait For Page Element
Alternatively, you can have Selenium wait for a specific element to appear on the page by using the wait_until argument.
Note: It is best to also include the wait arguement when using wait_until as if the element never appears, Selenium will hang and never return a response to Scrapy.
## spider.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(
url=url,
callback=self.parse,
wait_time=10,
wait_until=EC.element_to_be_clickable((By.ID, 'someid'))
)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
3. Scrolling The Page
To scroll the page down when dealing with infinite scrolling pages you can configure Scrapy Selenium to execute a custom JavaScript code.
## spider.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(
url=url,
callback=self.parse,
script='window.scrollTo(0, document.body.scrollHeight);',
)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
4. Take Screenshot
You can take a screenshot of the fully rendered page, using Selenium's screenshot functionality.
## spider.py
import scrapy
from selenium_demo.items import QuoteItem
from scrapy_selenium import SeleniumRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SeleniumRequest(
url=url,
callback=self.parse,
screenshot=True
)
def parse(self, response):
with open('image.png', 'wb') as image_file:
image_file.write(response.meta['screenshot'])
More Scrapy Tutorials
In this guide we've introduced you to the fundamental functionality of Scrapy Selenium and how to use it in your own projects.
However, if you would like to learn more about Scrapy Selenium then check out the offical documentation here.
If you would like to learn more about different Javascript rendering options for Scrapy, then be sure to check out our other guides:
If you would like to learn more about Scrapy in general, then be sure to check out The Scrapy Playbook.